商城网站建设的优势WordPress文字导航功能插件

商城网站建设的优势,WordPress文字导航功能插件,高端炫酷h5怎么制作,wordpress删了重装今天给大家分享一个强大的算法模型#xff0c;卷积神经网络算法
卷积神经网络算法#xff08;CNN#xff09;是一类专门用于处理具有网格结构数据的深度学习模型#xff0c;例如图像#xff08;2D像素网格#xff09;或时间序列#xff08;1D信号#xff09;。
CNN 的设…今天给大家分享一个强大的算法模型卷积神经网络算法卷积神经网络算法CNN是一类专门用于处理具有网格结构数据的深度学习模型例如图像2D像素网格或时间序列1D信号。CNN 的设计灵感来源于生物视觉皮层的结构它通过局部感受野、权值共享和下采样操作提取输入数据的层级特征从而降低参数量和计算复杂度同时保留空间结构信息。CNN 广泛应用于图像识别、目标检测、语义分割等任务。核心原理在处理高维图像数据时传统的全连接网络面临两个痛点参数量爆炸和忽略空间结构。例如一张 的彩色图像如果第一层有 1000 个神经元参数量将达到 30亿个这不仅难以训练还忽略了像素间的空间相关性。CNN 引入了三个关键机制来解决这些问题。局部感受野神经元只与输入层的一个局部区域连接模拟人类视觉皮层对局部特征的敏感性。权值共享在同一卷积层中卷积核Filter的参数在整个输入图像上是共用的这不仅大幅减少了参数还赋予了网络“平移不变性”。空间下采样通过池化减少数据的空间尺寸保留主要特征提高模型的鲁棒性。相比传统的全连接神经网络CNN 可以显著减少参数量同时自动提取空间层次特征。CNN 的基本结构一个经典的 CNN 模型通常由卷积层、激活函数、池化层和全连接层交替堆叠而成。1.卷积层卷积层是 CNN 的核心组件它通过卷积操作来提取输入数据中的局部特征。卷积操作的核心思想用一个小滤波器卷积核扫描输入数据的局部区域计算加权和从而提取特征。核心概念卷积核卷积核本质上是一个小型的权重矩阵用来学习输入数据的局部特征。每个卷积核可以检测输入的某种特征如边缘、纹理、角点多个卷积核可以提取多种特征生成多通道输出。步幅卷积核在输入上滑动的步长。填充为了保持卷积后输出的空间尺寸或避免丢失边缘信息常在输入图像的边缘加上零填充。2.激活函数卷积是线性运算为了引入非线性从而拟合复杂函数我们需要在卷积后叠加激活函数。常用激活函数有ReLUSigmoidTanh其中 ReLU 是最常用的计算简单且可以缓解梯度消失问题。3.池化层池化层的作用是对特征图进行下采样减少计算量和防止过拟合。池化负责降低特征图的空间维度下采样从而减少计算量并防止过拟合。常用的池化操作有最大池化和平均池化最大池化 (Max Pooling)取局部区域内的最大值保留最显著的特征。平均池化 (Average Pooling)取局部区域内的平均值保留背景信息。4.全连接层在多次卷积和池化后网络将多维的特征图“展平”Flatten为一维向量送入全连接层进行最后的分类或回归。在全连接层中每个神经元与前一层的所有神经元都有连接。训练过程CNN 的训练过程通常使用反向传播算法和梯度下降法来更新网络中的参数。包括以下步骤前向传播输入数据通过通过卷积、池化、全连接得到预测值。计算损失计算预测值与真实值的偏差。反向传播 通过反向传播算法计算损失函数对每个参数的梯度。更新参数通过梯度下降等优化算法如SGD、Adam等更新网络中的权重和偏置使得损失最小化。优势参数共享同一卷积核用于不同位置显著减少参数量。局部感受野卷积核只关注局部区域捕捉局部特征。平移不变性卷积和池化让模型对目标在图像中移动不敏感。适合高维数据可处理大图像避免全连接网络参数爆炸。自动特征提取无需手工设计特征案例分享下面是一个使用卷积神经网络算法PyTorch 版进行手写数字识别的示例代码。import torchimport torch.nn as nnimport torch.optim as optimimport torch.nn.functional as Ffrom torchvision import datasets, transformsimport matplotlib.pyplot as plt# 1. 定义网络结构class ConvNet(nn.Module): def __init__(self): super(ConvNet, self).__init__() # 第一层卷积输入1通道黑白输出32通道卷积核3x3 self.conv1 nn.Conv2d(1, 32, kernel_size3, padding1) # 第二层卷积输入32通道输出64通道 self.conv2 nn.Conv2d(32, 64, kernel_size3, padding1) # 池化层 self.pool nn.MaxPool2d(2, 2) # 全连接层MNIST图像28x28经过两次2x2池化后变为7x7 self.fc1 nn.Linear(64 * 7 * 7, 128) self.fc2 nn.Linear(128, 10) # 10个数字分类 def forward(self, x): x self.pool(F.relu(self.conv1(x))) x self.pool(F.relu(self.conv2(x))) x x.view(-1, 64 * 7 * 7) # 展平 x F.relu(self.fc1(x)) x self.fc2(x) return x# 2. 环境配置与数据准备device torch.device(cudaif torch.cuda.is_available() elsecpu)transform transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,))])train_loader torch.utils.data.DataLoader( datasets.MNIST(./data, trainTrue, downloadTrue, transformtransform), batch_size64, shuffleTrue)# 3. 实例化与优化器model ConvNet().to(device)optimizer optim.Adam(model.parameters(), lr0.001)criterion nn.CrossEntropyLoss()# 4. 训练与记录epochs 5history {loss: [], accuracy: []}for epoch in range(1, epochs 1): model.train() running_loss 0.0 correct 0 total 0 for data, target in train_loader: data, target data.to(device), target.to(device) optimizer.zero_grad() output model(data) loss criterion(output, target) loss.backward() optimizer.step() running_loss loss.item() _, predicted torch.max(output.data, 1) total target.size(0) correct (predicted target).sum().item() epoch_loss running_loss / len(train_loader) epoch_acc 100. * correct / total history[loss].append(epoch_loss) history[accuracy].append(epoch_acc) print(fEpoch {epoch}: Loss: {epoch_loss:.4f}, Acc: {epoch_acc:.2f}%)# 5. 绘制函数图像plt.figure(figsize(12, 5))plt.subplot(1, 2, 1)plt.plot(history[loss], labelTraining Loss, colorred)plt.title(Loss Curve)plt.xlabel(Epochs)plt.ylabel(Loss)plt.subplot(1, 2, 2)plt.plot(history[accuracy], labelTraining Accuracy, colorblue)plt.title(Accuracy Curve)plt.xlabel(Epochs)plt.ylabel(Accuracy (%))plt.show() 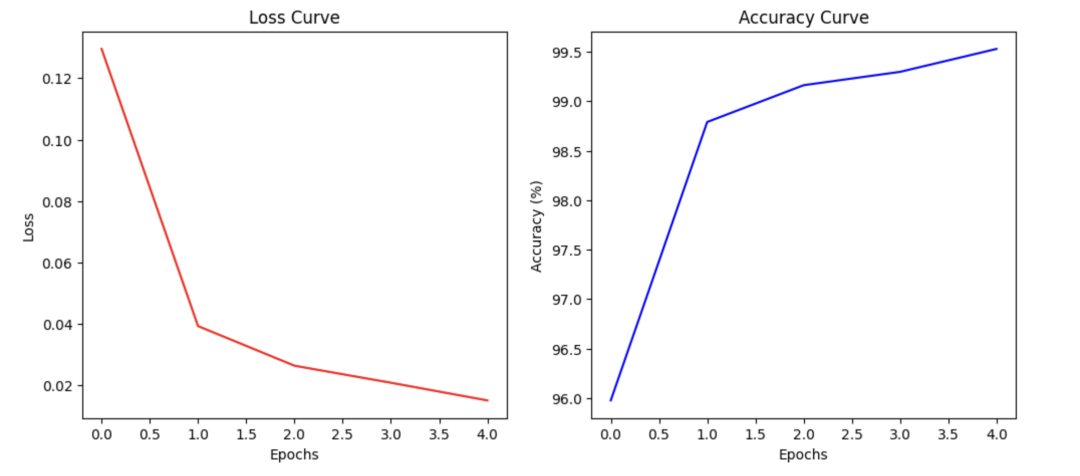plaintext import numpy as npdef visualize_results(model, device, num_samples10): model.eval() # 切换到评估模式 # 获取测试集数据 test_loader torch.utils.data.DataLoader( datasets.MNIST(./data, trainFalse, transformtransform), batch_sizenum_samples, shuffleTrue) data, target next(iter(test_loader)) data, target data.to(device), target.to(device) # 模型推理 with torch.no_grad(): output model(data) pred output.argmax(dim1, keepdimTrue) # 绘图 plt.figure(figsize(15, 6)) for i in range(num_samples): plt.subplot(2, 5, i 1) # 将张量转回图片格式 (C,H,W) - (H,W) img data[i].cpu().squeeze().numpy() # 反标准化以便观察可选 img img * 0.3081 0.1307 plt.imshow(img, cmapgray) # 结果比对 is_correct pred[i].item() target[i].item() color greenif is_correct elsered plt.title(fPred: {pred[i].item()}\nActual: {target[i].item()}, colorcolor) plt.axis(off) plt.tight_layout() plt.show()# 调用函数显示结果visualize_results(model, device, num_samples10)  **最后** — **今天的分享就到这里。如果觉得近期的文章不错请点赞转发安排起来。** **欢迎大家进高质量 python 学习群** **「进群方式加我微信备注 “python”」**  **往期回顾**   [Fashion-MNIST 服装图片分类-Pytorch实现](http://mp.weixin.qq.com/s?__bizMzU5NjE0NjI1MQmid2247486859idx1sn60bd671684ef0e8a3d1c7537a86b505bchksmfe666cafc911e5b9d9a6e3dfc769091769505c746a1468753c9bf23777c8733e7fd57dd594d9scene21#wechat_redirect)  [python 探索性数据分析EDA案例分享](http://mp.weixin.qq.com/s?__bizMzU5NjE0NjI1MQmid2247486931idx1sn6624ffa4d6207d496d7f4107b506af5cchksmfe666cf7c911e5e1bca87eabb038d16d3f589dc783a92a5d12e2a8a4887a8706b7f609af4be0scene21#wechat_redirect)  [深度学习案例分享 | 房价预测 - PyTorch 实现](http://mp.weixin.qq.com/s?__bizMzU5NjE0NjI1MQmid2247486679idx1snc07734de23df4f834fc9d8c3651b33a7chksmfe666df3c911e4e5b03b00a3cb0d2e75535c2f94fdd17631b713a8506d788a4ddd2ccdd7c6f2scene21#wechat_redirect)  [万字长文 | 面试高频算法题之动态规划系列](http://mp.weixin.qq.com/s?__bizMzU5NjE0NjI1MQmid2247486119idx1sn8ef439f31a9fe2695b48e5d67eb47fdechksmfe666b83c911e2950f00e5be3a2f9274dc561205c7da23192f3094b9722ea81977d0b01eb5ecscene21#wechat_redirect)  [面试高频算法题之回溯算法全文六千字](http://mp.weixin.qq.com/s?__bizMzU5NjE0NjI1MQmid2247486039idx1snb4614e27adbb6ea9949385f92c64b479chksmfe666b73c911e265a94801ae58162a592e849d6cc6d6e8efef91f1448f269df32d086c908052scene21#wechat_redirect)  如果对本文有疑问可以加作者**微信**直接交流。 最后唠两句为什么AI大模型成为越来越多程序员转行就业、升职加薪的首选很简单这些岗位缺人且高薪智联招聘的最新数据给出了最直观的印证2025年2月AI领域求职人数同比增幅突破200% 远超其他行业平均水平整个人工智能行业的求职增速达到33.4%位居各行业榜首其中人工智能工程师岗位的求职热度更是飙升69.6%。AI产业的快速扩张也让人才供需矛盾愈发突出。麦肯锡报告明确预测到2030年中国AI专业人才需求将达600万人人才缺口可能高达400万人这一缺口不仅存在于核心技术领域更蔓延至产业应用的各个环节。那0基础普通人如何学习大模型 深耕科技一线十二载亲历技术浪潮变迁。我见证那些率先拥抱AI的同行如何建立起效率与薪资的代际优势。如今我将积累的大模型面试真题、独家资料、技术报告与实战路线系统整理分享于此为你扫清学习困惑共赴AI时代新程。我整理出这套 AI 大模型突围资料包【允许白嫖】✅从入门到精通的全套视频教程✅AI大模型学习路线图0基础到项目实战仅需90天✅大模型书籍与技术文档PDF✅各大厂大模型面试题目详解✅640套AI大模型报告合集✅大模型入门实战训练这份完整版的大模型 AI 学习和面试资料已经上传CSDN朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】①从入门到精通的全套视频教程包含提示词工程、RAG、Agent等技术点② AI大模型学习路线图0基础到项目实战仅需90天全过程AI大模型学习路线③学习电子书籍和技术文档市面上的大模型书籍确实太多了这些是我精选出来的④各大厂大模型面试题目详解⑤640套AI大模型报告合集⑥大模型入门实战训练如果说你是以下人群中的其中一类都可以来智泊AI学习人工智能找到高薪工作一次小小的“投资”换来的是终身受益应届毕业生无工作经验但想要系统学习AI大模型技术期待通过实战项目掌握核心技术。零基础转型非技术背景但关注AI应用场景计划通过低代码工具实现“AI行业”跨界。业务赋能 突破瓶颈传统开发者Java/前端等学习Transformer架构与LangChain框架向AI全栈工程师转型。获取方式有需要的小伙伴可以保存图片到wx扫描二v码免费领取【保证100%免费】
更多精彩文章

上海网络公司网站建设青岛栈桥门票多少钱
中学数学几百年重大错误:将两异数列误为同一数列 黄小宁 医学若将前所未知的病毒误为熟悉的感冒病毒就会使许多人死于非命,“以严密、精确为生命”的数学将前所未知的数列(集)误为熟悉的数列(集)显然是致命…...

网站建设 翻译怎么才能找到想做网站建设的客源
第一章:Seedance 2.0角色特征保持技术避坑指南总览Seedance 2.0 在生成式角色动画中引入了基于语义对齐的特征冻结机制,但实际部署时常见因隐空间扰动、跨模态对齐偏差或训练-推理不一致导致角色身份漂移。本章聚焦典型失效场景与可立即落地的防御策略&a…...

攸县网站开发网站浮动窗口怎么做的
LightOnOCR-2-1B实战教程:Python调用API实现批量PDF截图文字提取 1. 引言 你有没有遇到过这样的烦恼?手头有一堆PDF文件,里面全是扫描的图片或者截图,想提取里面的文字,要么得手动一个字一个字敲,要么用传…...